CollectionBuilder-DHSI Workshop Tutorial
Resources for Understanding CollectionBuilder
Readings, links, overviews and other contextual information about CollectionBuilder
CollectionBuilder Resources
Websites and Repositories
-
CollectionBuilder main site (info and documentation), https://collectionbuilder.github.io/
-
CollectionBuilder GitHub organization (code repositories), https://github.com/collectionbuilder/
-
CollectionBuilder presentations repository, https://osf.io/5sevc/
-
University of Idaho Digital Collections (mostly CollectionBuilder-based), https://www.lib.uidaho.edu/digital/collections.html
-
Center for Digital Inquiry and Learning (University of Idaho digital scholarship unit, following mostly Lib-Static style development), https://cdil.lib.uidaho.edu/
CollectionBuilder Basics
CollectionBuilder is a set of flexible open source templates for creating digital collection and exhibit websites that are driven by metadata and powered by modern static web technology. To generate a digital collection website, users:
-
Create metadata in a spreadsheet
-
Organize a corresponding folder of digital objects (images, PDFs, videos, etc)
-
Make a copy of the CollectionBuilder template code
-
Configure and customize the site using built-in options
-
Write contextual content in Markdown
Once set up, the CollectionBuilder project is transformed by the popular static site generator Jekyll (installed on a laptop or used through an automatic build process such as GitHub Pages hosting service) into a complete website for browsing and contextualizing the collection. The output is static HTML that can be copied to any basic web server, or hosted for free on GitHub Pages, providing a simple, preformant, and secure website—alongside clean data and metadata ready for long term digital preservation.

CollectionBuilder templates are a packaged folder of plain text files, including modular chunks of HTML, CSS, and JS, and helpful development libraries such as Bootstrap. Users need not know anything about Jekyll, Liquid, or the other tools that power CollectionBuilder to get started. Instead, they begin by focusing on their collection’s metadata and digital objects independent of the system, then follow step-by-step documentation to add them to the project template.
The CollectionBuilder code consumes the collection metadata added by the user to automatically generate browsing features, items pages, data derivatives, and rich SEO markup. Metadata drives the core of the user interface, creating interactive browsing pathways and visualizations that encourage visitors to explore and discover content while also representing overall context, transforming high quality description into a rewarding user experience.

CollectionBuilder Workflow
To demonstrate how CollectionBuilder works, this section walks through our current pedagogical version, CollectionBuilder-GH, a tool intended as a simple template for hands-on teaching about digital libraries.
CollectionBuilder-GH can be used in a workshop or classroom setting to take participants through digitization and metadata creation, to having a live digital collection website hosted on GitHub Pages without installing any software (this contrasts with the other CollectionBuilder versions which rely on Jekyll being installed on a local development machine). The only requirement for both instructor and participants is a GitHub account and a web browser. Similar learning experiences often use Omeka or other DAMS/CMS platforms with extensive infrastructure requirements that are overkill for one-off projects. Although these platforms feature familiar GUI administration interfaces, they are not necessarily simple to learn and customize. CollectionBuilder-GH aims to be well documented and easy to configure by following the example—if you match the metadata template, a fully functional website will be automatically generated. Customization is learned in additional small steps, encouraging scaffolded learning about web and data fundamentals. A project in “minimal computing”, CollectionBuilder-GH provides a depth of learning opportunities, allowing users to take complete ownership over the project while making their work open to the world.
-
Setup: After getting set up with GitHub accounts and orientation, users start their new project by creating a copy of the code on GitHub by clicking the “Use this Template” button, https://github.com/CollectionBuilder/collectionbuilder-gh
-
Prepare Objects: Users then prepare their folder of digitized objects (generally images and/or PDFs) following the documented standards, and upload them into their project repository’s “objects” directory. This is an opportunity to teach data skills such as file naming, preservation formats, and media editing.
-
Prepare Metadata: Users prepare a spreadsheet of metadata for the objects, following the CollectionBuilder metadata template (which is based on digital libraries best practices and standards). We typically use Google Sheets, allowing easy collaboration with groups of participants. This hands-on digitization and metadata creation experience helps reveal the real labor and decision-making processes that go into the creation of digital library data. Skills learned manipulating media files and working with spreadsheets are more transferable data fundamentals than comparable workflows in CMS interfaces which focus on forms and clicks. Once the metadata is prepared, it is downloaded/exported as a CSV, and uploaded into their project repository’s “_data” directory.
-
Configure Site: With the well-structured data prepared, users can begin working on the website configuration, including the “_config.yml” which provides the base settings for Jekyll websites, such as site “title,” “tagline,” and “description.” Config files can be edited using GitHub’s web interface.
-
Add Descriptive Content: Users can edit content pages, such as the About page, to provide context for their collection. Page content is styled using Markdown, providing an easy to learn and write markup language.
-
Activate GitHub Pages: With the click of a button, users can activate GitHub’s free hosting service and have a live website in seconds. In the background, the platform automatically runs the static site generator (Jekyll) over the source code, outputs a complete website (HTML, CSS, JSON, and JS files), and serves it up to the world. Users navigate to their site to discover their new digital collection and explore the visualizations. They will likely discover interesting metadata anomalies that were not apparent when working on the spreadsheet—a teachable moment about how to debug your project!
By creating a collection using CollectionBuilder, students develop interwoven technical and critical skills, including fundamental data literacies related to controlled vocabularies, unique identifiers, and descriptive practice. These lessons are reinforced when their metadata is transformed into a digital collection on the web, inevitably surfacing anomalies, breakages, and misrepresentations tied to issues in the metadata that they return to the spreadsheet to fix. Small “next steps” invite students to start learning more about the templates generating the website, encouraging incremental development of further web skills.
Outside of the classroom or workshop setting, we still see CollectionBuilder as a tool rooted in learning. CollectionBuilder is unlike common Content Management Systems (CMS) or Digital Asset Management (DAM) platforms that most institutions use—it is not a visual GUI tool and there is no admin interface, which can intimidate and contribute to an initial learning curve. However, it is designed to be ‘do-able’ and accessible for librarians and digital humanities practitioners—and once understood, users will be rewarded with a flexible and sustainable template for creating digital collections, as well as data and web skills transferable to any digital project. This opportunity for professional development provides unique agency for librarians to take full control over their systems and pursue new initiatives and ideas equipped with CollectionBuilder components as a recipe book of solutions.
Using other versions of CollectionBuilder follows a similar workflow as described above, but allows for further customization, features, and optimization of the site. Users edit the template code on their own computers and run Jekyll to provide a local development server to test their work. The code aims to be modular, understandable, and well-documented with the goal to be sustainable for a low-resourced digital libraries team. Once a collection is ready to deploy, the developer uses Jekyll to build the self-contained static website and copies the files over to a basic web server or hosting service.
The Lib-Static Methodology
Since around 2015 static site generators and the “JAMstack” approach have exploded in the web development landscape—utilizing simplified markup, plain text data files, and web APIs to create complete websites without the need for complex server applications, databases, or content management systems. Rather than relying on server-side processing to generate a dynamic page on the fly for each user request, static web tools “pre-render” every page into HTML, CSS, and JS files that can be delivered directly to users with speed, efficiency, and security from the most basic web servers or services. This modern static web approach provides high performance for users, minimal infrastructure requirements for IT, and lower barriers for developers.
Eager to explore this potential in the library context, faculty librarians at the University of Idaho (U of I) have been developing digital collections, digital humanities projects, and instructional content using static web tools for more than five years. Informed by the philosophy of minimal computing, they have been documenting the “Lib-Static” methodology to begin building a community of practice centering digital infrastructure approaches around the unique needs, values, and opportunities of libraries.
The primary principles of the methodology are summarized in the visualization below:
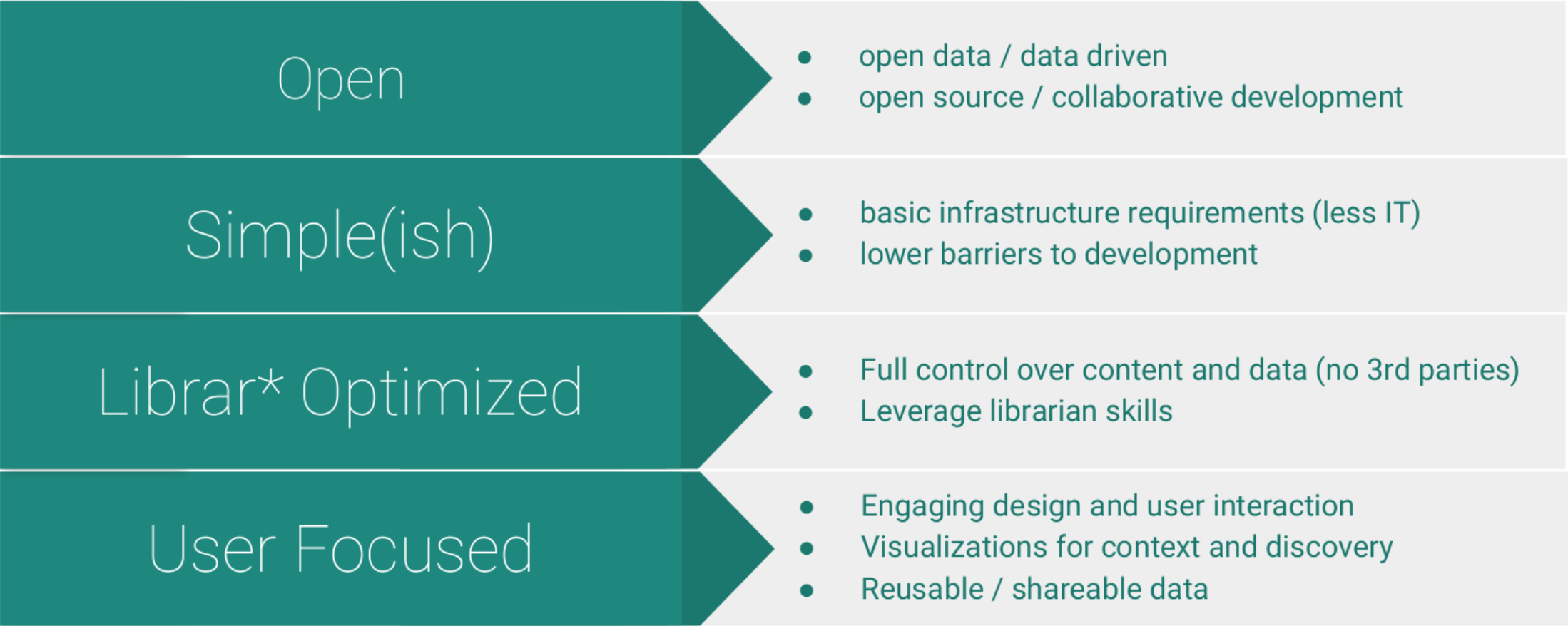
Simply stated, Lib-Static-inspired tools seek to apply the techniques of the modern static web approach to pragmatically solve problems in the digital library ecosystem. It differs greatly from the predominant model for platform and tool building for academic libraries as it does not require complex infrastructure nor extensive IT staffing (or third party vendors) to implement and maintain the systems put into use. Instead, the Lib-Static approach focuses on practical, sustainable workflows using data-driven static web templates hosted on simplified infrastructure while leveraging the in-house specialized skills of librarians in metadata, data, and organization. This provides librarians unique agency and ownership over their systems, as well as meaningful opportunities for professional development leading to fundamental digital skills (instead of the “buttonology” of a single platform). The focus on clean data and simple systems enables a more agile and responsive approach, allowing the iterative development of features, gradual acquisition of developer skills, and flexible migration between hosts without the need for deep investment.
Lib-Static acknowledges that all digital projects require investment in learning and seeks to maximize the local impact and value of learning during the process, while establishing technical solutions and social workflows that more closely match the structure of academic work cycles and needs. The simplified infrastructure and development environment of static web approaches are uniquely suited to enable:
-
Periods of focused development and collaboration, followed by much longer periods of minimal maintenance.
-
Project work focused on creating data independent of platform, which simplifies the initial infrastructure decision points and overhead while ensuring preservation- and migration-ready content.
-
Rapid design and data iterations—building projects in smaller steps allows data to be published faster, getting feedback earlier with less initial investment yet future opportunity for phases of progressive enhancement.
-
A focus on modular components, templates, and recipes that encourage learning investment on one project leading to efficiencies on another, building complementary work that powers further research and learning.
-
Public documentation and sharing, making investment more reusable while creating artifacts of learning alongside research and publications.
The Lib-Static methodology has grown out of U of I librarians’ experience collaborating with faculty, students, staff, and other organizations to create digital collection, digital scholarship, and teaching projects. Bogged down in the process of standing up and maintaining heavy infrastructure platforms for one off projects, they found a real need for a more flexible and sustainable approach to creating websites. The static web approach has freed up energy and time to pursue new initiatives and ideas, leading to unique collaborations and learning opportunities. Projects have included an open music text book, workshop outlines, interpretive oral history projects, a scholarly translation edition, scientific research archives, classroom digitization experiences, community digital collections, Special Collections exhibits, and the main library website–the Lib-Static methodology has truly infused our work! Each collaboration has advanced new solutions, features, and concepts which have in turn contributed to the development of several refined templates designed as reusable tools or bases for adaption, including Oral History as Data and CollectionBuilder.
Readings
Becker, Devin, Evan Williamson, and Olivia Wikle. “CollectionBuilder-CONTENTdm: Developing a Static Web ‘Skin’ for CONTENTdm-based Digital Collections,”* Code4Lib Journal* 49, 2020, https://journal.code4lib.org/articles/15326
Dombrowski, Quinn. “Sorry for all the Drupal: Reflections on the 3rd anniversary of ‘Drupal for Humanists,’”* Quinn Dombrowski* (blog), November 8, 2019, http://www.quinndombrowski.com/?q=blog/2019/11/08/sorry-all-drupal-reflections-3rd-anniversary-drupal-humanists
Gil, Alex. “The User, the Learner, and the Machines We Make.” Minimal Computing, May 21, 2015, https://go-dh.github.io/mincomp/thoughts/2015/05/21/user-vs-learner/
Nowviskie, Bethany. “speculative collections.” Bethany Nowviskie (blog), October 27, 2016, http://nowviskie.org/2016/speculative-collections/.
Russell, John E., and Merinda Kaye Hensley. “Beyond buttonology,” College & Research Libraries News, 2017, https://crln.acrl.org/index.php/crlnews/article/view/16833/18427
Varner, Stewart. “Minimal Computing in Libraries: Introduction.” Minimal Computing, January 25, 2017, https://go-dh.github.io/mincomp/thoughts/2017/01/15/mincomp-libraries-intro/
Visconti, Amanda. “Introducing Static Sites for Digital Humanities Projects (why & what are Jekyll, GitHub, etc.?),” Literature Geek, December 8, 2015, http://literaturegeek.com/2015/12/08/WhyJekyllGitHub
Wikle, Olivia, Evan Williamson, and Devin Becker. “What is Static Web and What’s it Doing in the Digital Humanities Classroom?” dh+lib, Special Issue: Literacies in a Digital Humanities Context, 2020, https://dhandlib.org/what-is-static-web-and-whats-it-doing-in-the-digital-humanities-classroom/
Williamson, Evan, Olivia Wikle, Devin Becker, Marco Seiferle-Valencia, Jylisa Doney, and Jessica Martinez, “Using Static Web Technologies and Git-based Workflows to Re-Design and Maintain a Library Website (Quickly) with Non-Technical Staff.” College & Undergraduate Libraries, 2021, (PDF included in this packet)